
[7]Building LLM Applications for Production-Prompt Engineering, Fine Tuning and RAG
How to build enterprise grade LLM applications?


Different ways to build with LLMs include training models from scratch, fine-tuning open-sourced models, and retrieval augmented generation(RAG). The stack discussed in this piece is still evolving and may change substantially as the underlying technology advances.
There are challenges with prompt engineering —
Ambiguous output format — We can craft our prompts to be explicit about the output format, but there’s no guarantee that the outputs will always follow this format
Incosistanecy in user experience — LLMs are stochastic; there is no guarantee that they will give you the same output for the same input every time
1. How to do Promt Engineering?
One can take a three-step approach to make your model behave according to your prompts.
a. Prompt Evaluation
I recently tried the fewshot technique on a few projects on Searching relevant information from a large file based on NLP and Text-to-SQL. Fewshot technique for prompt engineering is to provide in the prompt a few examples and hope that the LLM will generalize from these examples.
When doing fewshot learning, two questions to keep in mind:
Whether the LLM understands the examples given in the prompt — We can evaluate this using the same examples as inputs, and observing whether the model generates the expected scores is one method to assess this. It’s possible that the prompt is unclear if the model doesn’t perform well on the same examples provided in it. You might wish to reword the question or divide the assignment into smaller tasks.
Whether the LLM overfits to these fewshot examples — You can evaluate your model on separate examples.
b. Prompt Versioning
Small changes to a prompt can lead to very different results. It’s essential to version and track the performance of each prompt. You can use git to version each prompt and its performance, but there will be tools like MLflow or Weights & Biases for prompt experiments.
c. Prompt Optimization
Generate multiple outputs from the same prompts and pick the final output by either the majority vote (also known as the self-consistency technique by Wang et al., 2023), or you can ask your LLM to pick the best one. The second way is to prompt the model to explain or explain step-by-step how it arrives at an answer, a technique known as Chain-of-Thought or COT. However, it can increase cost and latency due to increased output tokens.
2. Prompting vs Fine Tuning vs RAG
a. Prompting
For each sample, explicitly tell your model how it should respond. While making a model understand your context, the input context window might increase depending upon the complexity of your use case. For e.g., if your model needs to know 50 different unique parameters to get the accurate output, then every time the user queries an LLM model, it needs to take the context of these 50 different parameters every time. This increases the cost overall cost as it is also dependant on the number of input tokens. Also, the performance of the model scales inversely with the prompt size.
b. Fine Tuning
Fine-tuning is training a model on how to respond, so you don’t have to specify that in your prompt. According to the research, How many data points is a prompt worth?; a prompt is worth 100 examples given to the model while fine tuning it on a particular task. The general trend is that as you increase the number of examples, finetuning will give better model performance than prompting. There’s no limit to how many examples you can use to finetune a model.
The benefit of finetuning is two folds:
You can get better model performance by using more examples, which become part of the model’s internal knowledge.
You can reduce the cost of prediction. The more instruction you can bake into your model, the less instruction you have to put into your prompt. Say, if you can reduce 1k tokens in your prompt for each prediction, for 1M predictions on gpt-3.5-turbo, you’d save $2000.
While comparing prompting and fine tuning, there are 3 factors to be considered — data availability, performance and cost.
c. Retrieval Augmented Generation(RAG)
Limitations of Off-the-shelf LLMs
Only know what they are trained on
Context size is limited
Bad scaling with increasing context
Limited to text perception
Hard to evaluate the results
Expensive for high volumes of data
Why RAG?
LLMs are unaware of concepts outside of their training set
Filling gaps in knowledge with assumptions
Very hard to teach LLMs about new concepts
Then we give data input to the LLM — which means adding context to LLMs by integrating the retrieval system. Retrieval systems provide a short but informative context to LLMs, consisting of embedding models and vector databases.
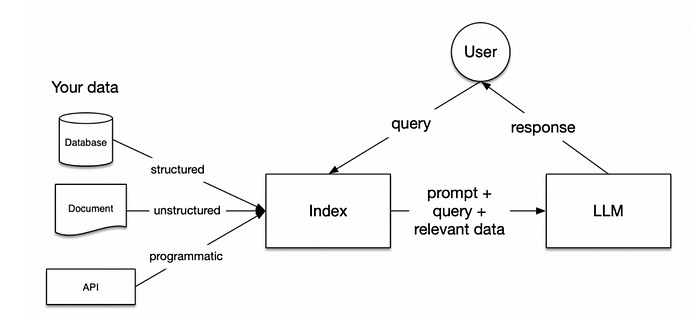
Deep down into evolving RAG techniques
a. Advanced Retrieval Strategies
Time Weighing — you can add a time component in your context window to control the time window of retrieval
Relevance Reorganization — where you ask another LLM to reorder the document that you retrieved in a way that reorders the most important documents first
Contextual Compression — where you ask another LLM to remove irrelevant parts of the documents resulting in a much better summarized and efficient context
Self Querying — where you ask another LLM to take your user query to convert it into a structured query
b. FLARE(Forward Looking Active Retrieval)
Retrieve documents based on query
Predict next sentence
If uncertainty is high, use a sentence as a query to retrieve more documents (For more details, visit research by Cornell University)
c. Orchestrating Partial Context LLM Instances — For large context windows
Define context chunks to provide each instance
Provide context chunks to multiple instances
Define merging strategies for outputs
Repeat until all chunks have been processed

If you found this piece helpful or interesting, don’t hesitate to share it with your network.